|
|
|
|
|
| (Introduction) | Contents | Index | (CA in SCARLET..) |
We approach the definition of CA
by examining the definition of cellular spaces first:
A 5-tuple
|
Are you already in the mood to give up? We hope not, because although precise definitions are sometimes a bit abstract and difficult to see through, the idea of CA hidden somewhere between the lines, is amazingly concrete:
First of all we consider a single Moore-automaton, which has got
''Could you please repeat at which point exactly I should have got the
idea of it???'' Really, did it not become clear? Whenever we speak of an
automaton in daily life, we most of the time actually mean an object that
can theoretically be described by a
Moore-automaton!
You cannot believe that? Perhaps the following example will convince you:
''Ok, ok; but what have Moore-automata to do with
cellular spaces?''
That will be the next step; in fact a cellular space consists of an
infinite number of automata of the same type, which are communicating with
each other. - But let us return to our example:
Besides we consider all IO-A to be in the same rhythm of time, that means the periods of input, output, and delay happen for all of them to be at the same time.
By consequence of this construction, each automaton has got a left and a right
neighbour, whose outputs will determine its input.
Conversely its own output will influence the inputs of other
IO-A.
Because of the fact that
![]() is bijective, we can identify the output
of an IO-A with the state it has at that moment and could, therefore, say:
is bijective, we can identify the output
of an IO-A with the state it has at that moment and could, therefore, say:
(Since cellular spaces are always constructed of
Moore-automata with
bijective output function
![]() ,
it is not longer necessary to speak
of input and output. It is convenient to care about
the states instead.)
,
it is not longer necessary to speak
of input and output. It is convenient to care about
the states instead.)


''But who tells us we've chosen the right function
![]() ?
The definition doesn't tell anything about that! Anyway, what about this
strange n-tuple that is said to be the
neighbourhood? It seems that it isn't
useful at all, otherwise it would have been already mentioned?!''
?
The definition doesn't tell anything about that! Anyway, what about this
strange n-tuple that is said to be the
neighbourhood? It seems that it isn't
useful at all, otherwise it would have been already mentioned?!''
Just a moment! These points are still unclear, because we have always
emphazised that cellular spaces are accumulations
of single automata with a
high degree of independence. But in fact one focuses on the cellular space as
a whole, with a homogeneous behaviour and regards the automata only as its
components. (That is the reason why they
are also called
cells (or sites).)
The following definitions allow the use of such a point of view that
looks at a cellular space in its totality, and, therefore, complete our
explanations:
|
A mapping
ct(i),
Suppose that A denotes an alphabet,
For all
|
The most important tool to look at a cellular space as a whole seems to be
the configuration: Each configuration presents the states of all
automata at
a certain time step. Consequently now we are looking for a (global) mapping
![]() that will convert in a suitable way whole configurations.
We have found the right one, when its global actions can be reduced on
the local effects of
that will convert in a suitable way whole configurations.
We have found the right one, when its global actions can be reduced on
the local effects of
![]() on every cell. - Obviously this is only
possible, if the elements of the cellular space, the
automata, are homogeneous!
on every cell. - Obviously this is only
possible, if the elements of the cellular space, the
automata, are homogeneous!
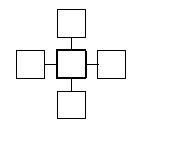
In the example given above, those cells that had an influence on the
successor state of another cell were also its spatial
neighbours.
Because that is a general (though not necessary) phenomenom, one speaks just
of "neighbours with regard to a certain neighbourhood",
when those cells
which are the arguments of the local rule function
![]() for a certain site, are meant, or in more
formal terms:
for a certain site, are meant, or in more
formal terms:
|
Suppose that
|
In other words, the neighbourhood indicates the relative positions of an
arbitrary cell to its neighbours.
In particular a cell may be its own neighbour, if N
contains the component
![]() .
.
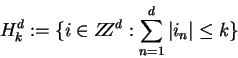
Unlike the Moore-automata mentioned in the beginning, the main purpose
of cellular spaces is not the construction of real existing machines, as
well as software, which is e.g., capable of pattern recognition and so on,
but the discrete simulation of continuous systems, as known,
for instance, from
the natural sciences, for both a better
comprehension of the theory of dynamical systems, and practical
calculations.
Therefore, not seldom cells are intended to model discrete points of a
system in
![]() ;
states contain discrete physical quantities or they
just tell, if there is a particle located in that point; and the
local rule
is meant to imitate some laws of nature.
;
states contain discrete physical quantities or they
just tell, if there is a particle located in that point; and the
local rule
is meant to imitate some laws of nature.
Because all real existing systems are subject to certain material
restrictions - probably this is less obvious for real systems than for
simulation systems - we are usually more interested in a finite form of
cellular spaces: the cellular automaton (CA).
Suppose that
|
In contrast to cellular spaces the area of interest of a
CA lies within a fixed subset of
![]() ,
the so-called retina. The last condition of
2., which demands that the cells are organized in undisrupted lines along
the coordinate axes, guarantees that the set is a connected domain.
,
the so-called retina. The last condition of
2., which demands that the cells are organized in undisrupted lines along
the coordinate axes, guarantees that the set is a connected domain.
It is bounded by the set B, that means that
B contains all cells
which are neighbours of cells within the range of the retina, but which are
not lying in the interior themselves. Therefore, B is called
boundary or border.
All cells on the boundary - and only those - remain in a particular state
# all the time; so their influence on the retina is always the
same.
Furthermore those cells lying behind the boundary are - because of the definition
of B - neighbours to no cell in retina and, therefore, do not have any
influence on it.
If we are only interested in the behaviour of a cellular space within a
certain area, we do not need to hesitate to forget the world behind the
boundary. We could assume, for instance, that all cells there have got
the quiescent state at t = 0.
|
|
|
|
|
| (Introduction) | Contents | Index | (CA in SCARLET..) |